A few days ago, I reposted a prompt claiming DeepMind used it to win Gold at IMO 2025, which seemed like a pleasant discovery. But the plot thickened - it turns out this prompt was actually used by a UCLA team with Gemini 2.5 Pro to achieve Gold Medal level performance. This makes it an even bigger deal.
- General LLMs have HUGE untapped potential in math and reasoning - we're just scratching the surface.
- Prompting is becoming a real art form and a powerful competitive moat for AI applications.
- RLVR totally works - even when implemented purely through prompting, no weight updates needed!
Brilliant System Design
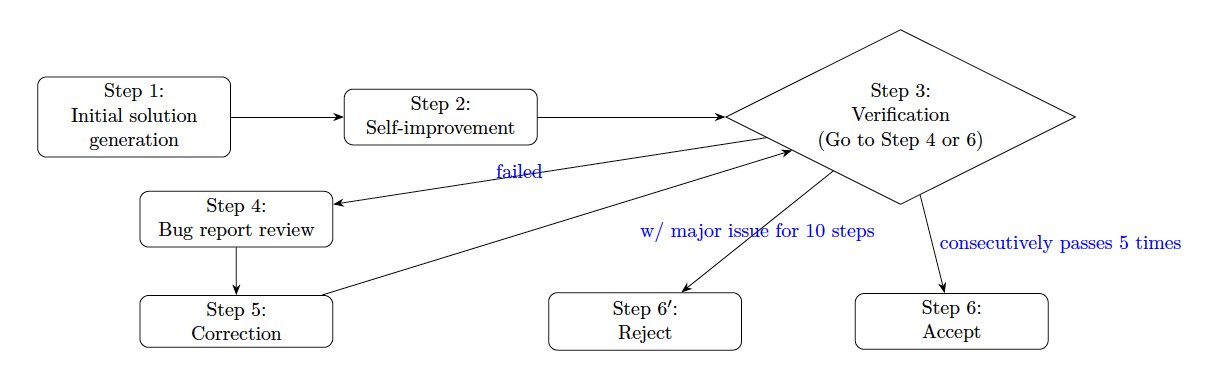
After reading the paper and codebase for several times, I have to say these two researchers designed a brilliant system. They run 10 parallel agents to solve each problem, with each agent operating as a completely independent process. Since Gemini 2.5 Pro has a 32k thinking token limit, they cleverly split the process into stages. The second stage, "self-improvement," feeds all previous content into a fresh API call, effectively doubling the thinking budget to 64k tokens.
Then comes verification. Using a specialized prompt, the LLM acts as an IMO grader, providing detailed feedback about errors and gaps. The verifier classifies issues into two types: Critical Errors (breaking the logical chain) and Justification Gaps (incomplete reasoning). This structured feedback loops back for corrections. The cycle continues for up to 30 iterations, until the solution passes verification 5 consecutive times. The system also knows when to give up - after 10 consecutive verification failures, it moves on.
RLVR Through Prompting Alone
This mirrors RLVR perfectly: massive sampling → structured feedback → iterative improvement. The verification prompt essentially creates a "reward model" through prompting alone. It's also test-time scaling in action - more thinking time yields better results. RLVR works not just in training, but in pure prompting!
However, the costs are substantial. Each correction creates an entirely new conversation context:
Round 1: [system_prompt] + [problem] + [self_improvement]
Round 2: [system_prompt] + [problem] + [solution1] + [correction_prompt] + [error_report1] → solution2
Round 3: [system_prompt] + [problem] + [solution2] + [correction_prompt] + [error_report2] → solution3
Round 4: [system_prompt] + [problem] + [solution3] + [correction_prompt] + [error_report3]
And so on...
With 10 parallel agents and multiple rounds per agent, costs explode exponentially. You also lose all KV cache efficiency since each round starts fresh. The system uses process-level parallelism rather than async IO, allowing true concurrent API calls despite using synchronous requests.
The Takeaway
While not production-ready for most applications due to cost, the RLVR design pattern is inspiring. It shows that with clever prompting alone, we can implement sophisticated training techniques at inference time.
We need more creative methods like this to truly unleash what these trillion-parameter beasts are capable of.